Building the Right Infrastructure for AI Agents in Life Sciences R&D
At Kepler AI, we build enterprise-grade AI agents for life sciences applications to accelerate scientific discovery. Since launching our bioinformatics and data science agent, we’ve been approached by many companies eager to develop their own AI agents for R&D workflows. Because we think about these challenges every day, we want to share some key lessons—starting with one of the most critical (and often overlooked) foundations: software infrastructure for code execution isolation. If you’re considering building scientific R&D agents that need to process data, this is where you should begin.
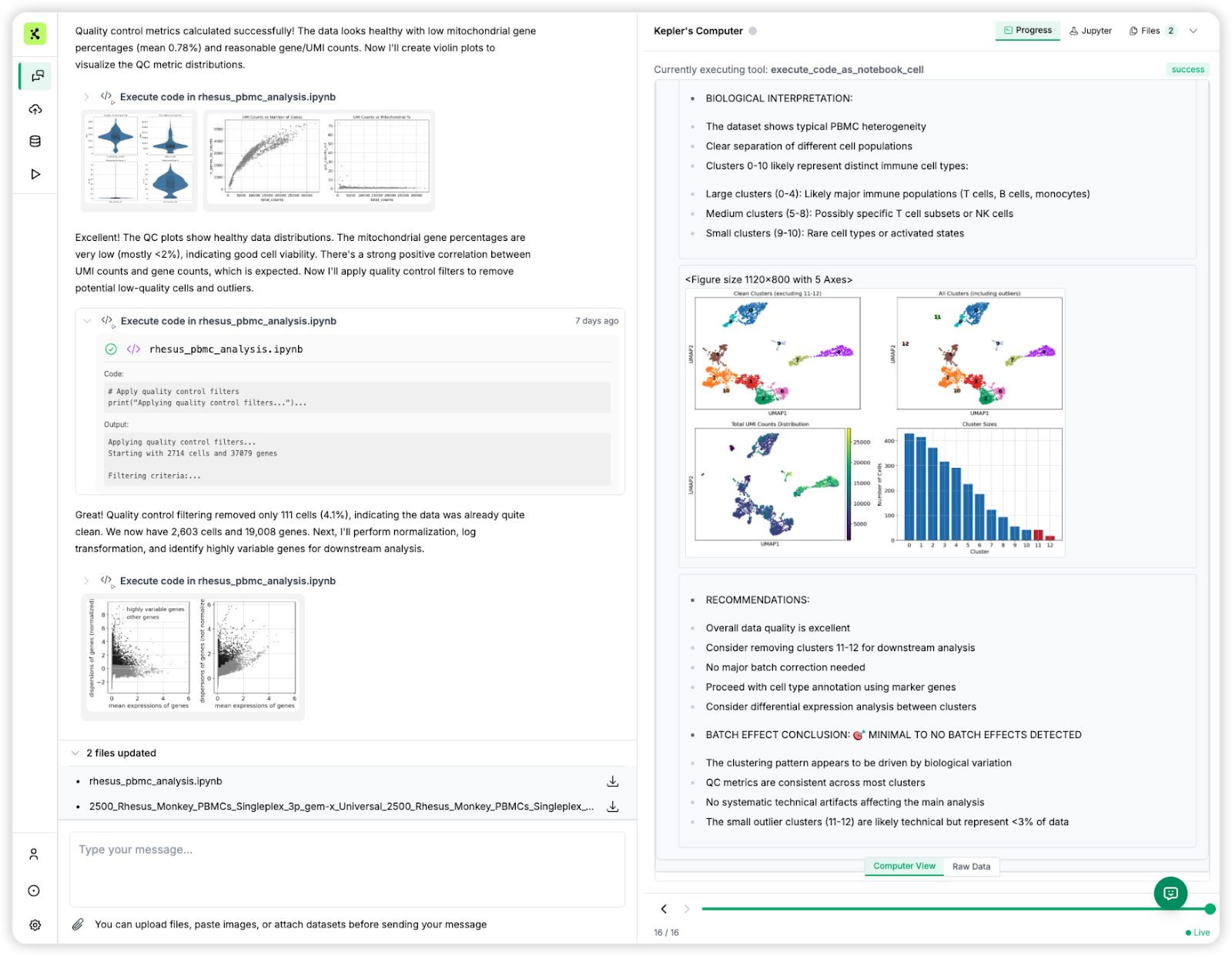
Deploying AI agents in life sciences R&D isn’t just about stringing together scientific tooling. It is also about trust, reproducibility, and security.
Consider an AI agent that doesn’t merely answer questions, but also:
- Generates and executes code against sensitive research data and proprietary algorithms
- Processes multi-gigabyte datasets that push the limits of compute and memory
- Accesses internal resources while maintaining strict boundaries between research teams
- Integrates multiple data sources in parallel without a single byte of cross-contamination
- Stops and resumes long-running analyses for days or weeks without losing state
The central challenge becomes clear: how can an AI system safely run untrusted code at this scale without putting data or organizations at risk, while achieving the goal of accelerating scientific discovery?
Most teams begin with containers, as they are a natural starting point. Yet as we will see, container-level isolation does not provide the level of security and reliability that scientific R&D requires.
From Localhost to Production Scale
When teams start building AI agents, the journey usually follows a familiar path—moving from scrappy prototypes on laptops to enterprise-grade orchestration at scale.
Level 1: Local Development
Almost everyone begins here: running an AI agent directly on a developer’s laptop. It’s fast, simple, and great for prototyping. Tools like Claude Code, Gemini CLI, or various agent frameworks make it easy to spin up an agent loop and see results.
But pretty quickly, the cracks start to show:
- Compute & memory bottlenecks: Multi-gigabyte datasets and complex statistical methods quickly overwhelm consumer hardware.
- Zero isolation: The agent runs with the developer’s identity and configuration—meaning sensitive data is at risk, and one bad hallucination can wreak havoc on the local environment.
- Dependency chaos: Sharing libraries between humans and agents often leads to version conflicts and unstable environments.
Level 2: Dedicated Infrastructure
To break free from laptop limits, teams usually move to dedicated servers or HPC clusters. This solves raw compute issues—but introduces new headaches:
- Configuration headaches: Reproducing scientific environments with domain-specific tools is harder than it looks.
- Resource contention: Multiple agents fighting over the same resources lead to unpredictable performance.
- Security blind spots: Shared execution environments leave the door open for one agent’s code to snoop on another’s data.
Level 3: Container Orchestration
Finally, teams turn to orchestration frameworks like Slurm or Kubernetes, where containerization becomes the foundation. Containers allow each agent task to run in a clean, reproducible environment—solving many of the problems from earlier stages.
- With Slurm: Agent tasks can be packaged as batch jobs with precise resource requirements.
- With Kubernetes: Jobs are defined with structured inputs (queries, datasets, cloud storage), controlled outputs (results with access policies), and fine-grained resource specs.
Orchestration platforms solve resource headaches, but they leave a blind spot wide open: security. Container-level isolation isn’t enough—true protection requires the stronger walls of VM-level sandboxing.
Why VM-Level Isolation is Essential
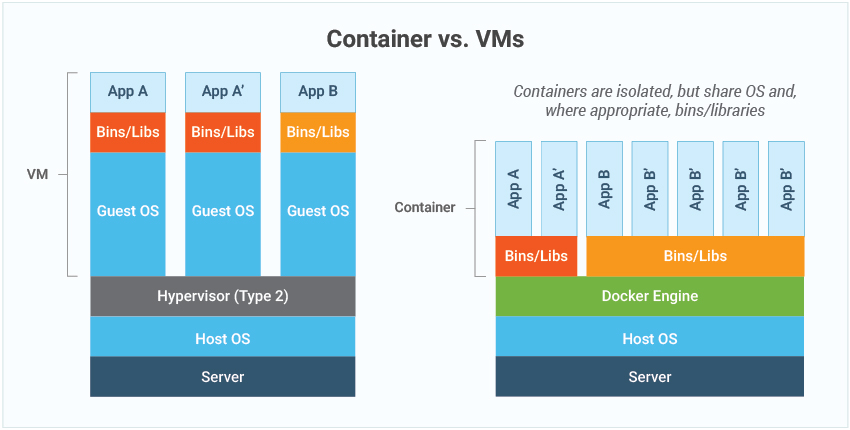
Containers are fantastic for packaging and deployment, but they all share a common weakness: the host machine’s kernel. For everyday applications, that tradeoff is usually fine. But in scientific R&D—where agents execute untrusted, AI-generated code on sensitive data—it’s a dealbreaker.
Here’s why container-only isolation falls short:
- A shared attack surface: If one container is compromised, the attacker doesn’t just get into that container—they may gain access to the host system and every other container running on it.
- Software walls, not hardware walls: Containers rely on namespaces and cgroups—software-level constructs that can’t match the robustness of true hardware-enforced isolation.
- A history of escapes: Time and again, vulnerabilities have been discovered that let malicious code break free from container boundaries.
- Memory interference risks: Containers share the host's memory management, which can lead to resource contention and unpredictable performance when one container's memory usage affects others. This is particularly problematic for memory-intensive scientific workloads that need consistent, predictable resource allocation.
- Network boundary gaps: Container networking relies on software-defined networks that share the host's network stack, creating potential pathways for cross-container communication and data leakage—even when applications are designed to be isolated.
For life sciences applications that process sensitive research data and execute AI-generated code, these risks simply aren’t acceptable.
Kepler's Solution: Micro-VM Sandboxes
At Kepler AI, we’ve tackled the limitations of containers by adopting the open-source sandbox environment built by E2B. This framework powers our agents with secure, lightweight computers based on Firecracker microVMs—the same technology Amazon uses to run millions of Lambda and Fargate workloads.
With this approach, each agent task runs inside its own dedicated virtual machine, protected by hardware-enforced security boundaries. On top of E2B, we’ve engineered additional optimizations specifically for high-performance life sciences workloads.
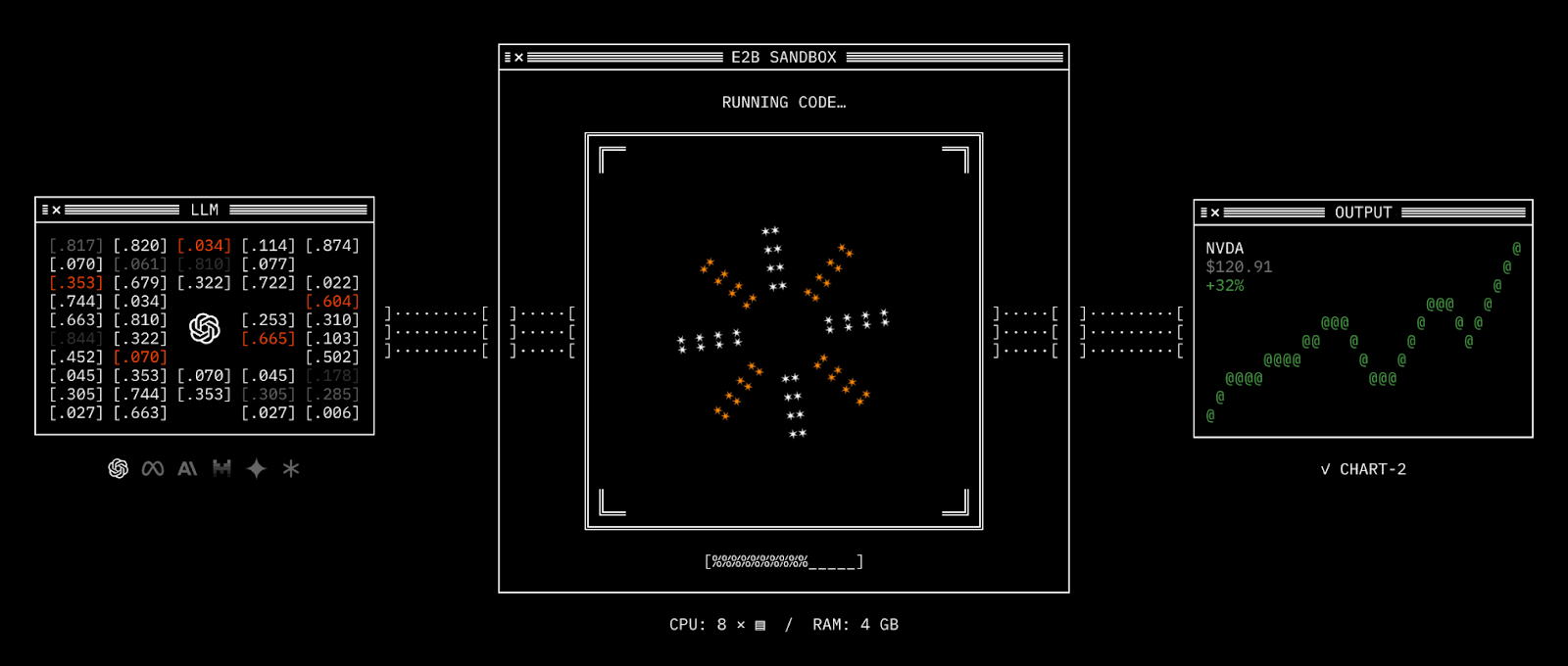
Here’s why micro-VM sandboxes are essential for R&D:
1. Hardware-Enforced Security
- Each agent runs with its own kernel, memory, and virtualized hardware.
- Eliminates the entire class of container escape vulnerabilities.
2. Multi-Tenant Scientific Collaboration
- Biotech R&D often spans multiple projects and collaborators, each with proprietary datasets.
- VM isolation guarantees zero data leakage across workloads while still sharing infrastructure.
- Research teams get strict, enforceable project boundaries.
3. Safe AI Code Execution
- Life sciences agents often generate and run code on the fly.
- Micro-VMs provide the flexibility to execute this code securely—without risking contamination of other tasks.
- Malicious or failed code stays fully contained inside the VM.
4. Versioning & Revertability
- Kepler integrates micro-VMs with a versioned storage layer for both tabular and unstructured data.
- Agents can branch, mutate, and experiment without touching the primary data source.
- Researchers can easily review, revert, or even time-travel across changes.
Advanced Capabilities for Scientific Workflows
Snapshot and Resume for Long-Running Analysis
Scientific R&D workflows often involve analyses that run for hours—or even days—before users return to them. Traditional container approaches break down here: keeping containers running is prohibitively expensive, and restarting wipes out valuable intermediate state.
Our micro-VM architecture solves this by enabling true pause-and-resume workflows:
- Full state preservation: Filesystem, memory, running processes, and loaded variables are all captured in the snapshot.
- Fast operations: Pausing takes about 4 seconds per GB of RAM; resuming takes ~1 second.
- Extended persistence: Sandboxes can remain paused for up to 30 days.
- Cost optimization: Users can pause expensive computational environments and restart exactly where they left off.
This means researchers can run long, complex analyses without fear of losing progress—or burning unnecessary compute costs.
Production-Scale Orchestration
Scaling beyond individual sandboxes requires orchestration that’s both intelligent and resilient. Our platform delivers this across three pillars:
- Resource Management
- Dynamic allocation based on computational demand
- Smart node scheduling to maximize efficiency
- Automatic scaling to handle workload spikes
- Access Control & Governance
- Fine-grained permissions for datasets and storage buckets
- Strict project-based isolation to prevent data leakage
- Comprehensive audit trails for regulatory compliance
- Operational Excellence
- Continuous health monitoring with automatic recovery
- Load balancing across compute nodes
- Robust error handling and retry logic for transient failures
At Kepler AI, this architecture can support over 1,000 concurrent agent tasks, each handling computationally intensive bioinformatics workloads—all while maintaining the security and isolation standards life sciences organizations demand.
Conclusion
Building AI agents for life sciences R&D requires more than powerful models. It requires infrastructure that delivers security, isolation, reliability, and trust.
While containers work well in many enterprise settings, they fall short for scientific workflows. Life sciences R&D must protect sensitive datasets, execute AI-generated code safely, support multiple teams working in parallel, and preserve state for analyses that run over days or weeks. Only VM-level sandboxing with snapshotting and persistence provides these features.
For life sciences organizations, the infrastructure choice is no longer just technical—it is a strategic decision that safeguards trust, compliance, and scientific integrity.

Connect the dots with Kepler
Try out Kepler today, or book a call with us about your organization's use case
Connect the dots with Kepler
Try out Kepler today, or book a call with us about your organization's use case
